S2 : slurm profiling¶
Although nn_seff command is a quick and easy way to determine the resource utilisation, it relies on peak values (data gets recorded every 30 seconds) which doesn't allows us to examine resource usage over the run-time of the job. There are number of in-built/external tools to achieve the latter which will require some effort to understand its deployment, tracing and interpretation. Therefore, we will use slurm native profiling to evaluate resource usage over run-time. This is a simple and elegant solution.
The below is an example only. sh5util currently not installed on the REANNZ HPC (as of April 2026). An alternative approach will eventually be updated here.
Exercise S.2.1
-
Download and decompress the content
-
Run
lscommand and you should see three files (one .R,sl and one .py - We will discuss the purpose of this .py file after submitting the job) and one directory named slurmout -
Review the slurm script with cat Or another text editor and submit with sbatch
-
Do take a note of the JOBID as we are going to need it for next step. Otherwise, we use
squeue --meORsacctcommand as before to monitor the status - Also, you can
watchthe status of this job via$ watch -n 1 -d "squeue -j JOBID". -
watchcommand execute a program periodically, showing output fullscreen. Exiting thewatchscreen by done by pressingCtrl+x -
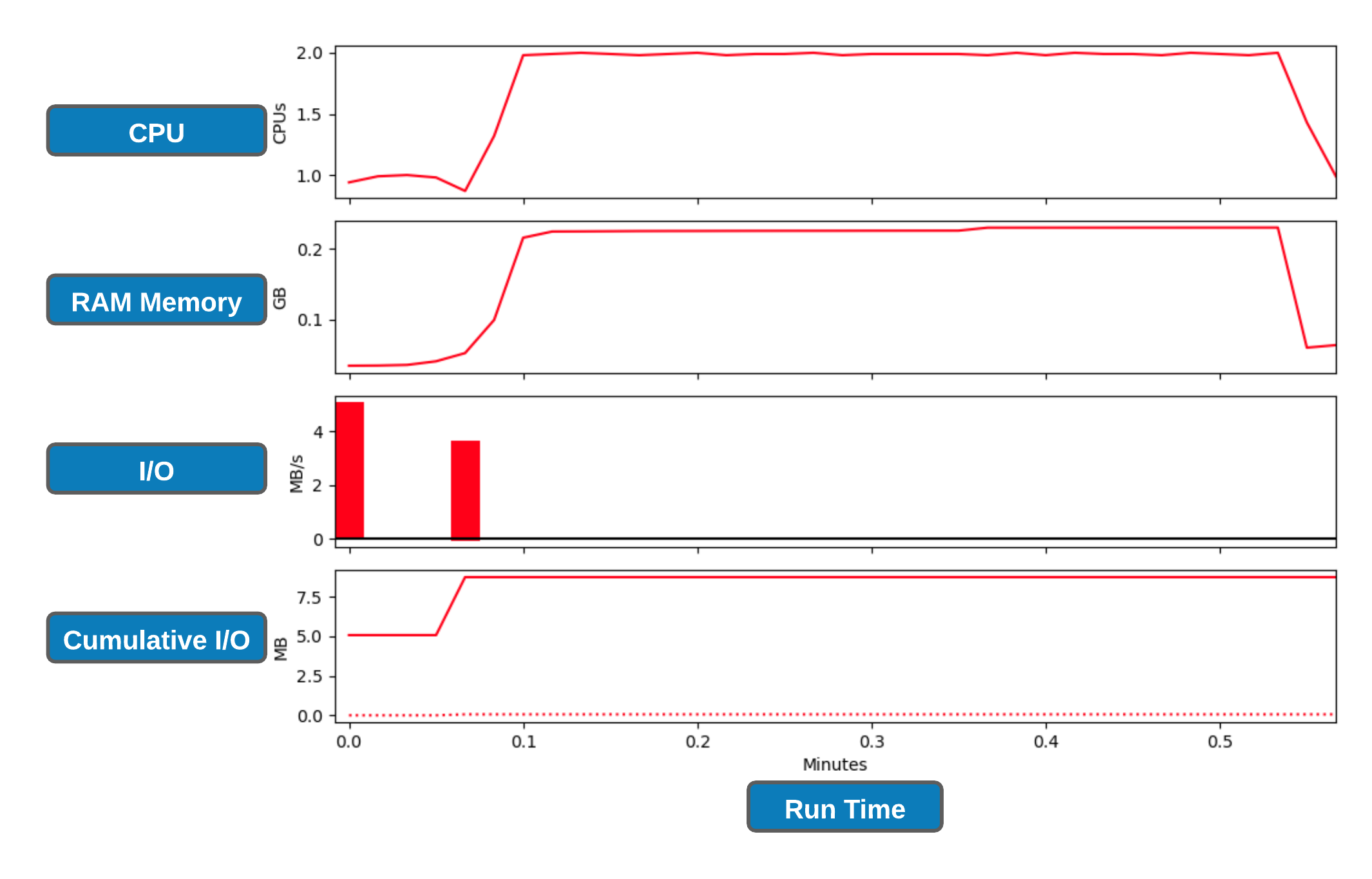
Let's create slurm profile graphs
-
collate the data into an HDF5 file using the command. Replace JOBID with the corresponding number
-
execute the script on .h5 file. We will need one of the Python 3 modules to do this. Ignore the deprecating warning.
-
Replace JOBID with the corresponding number
-
This should generate a .png file where the filename is in the format of job_23258404_profile.png
-
Note: This figure will also provide information on GPU CPU and memory usage if you are using a GPU.
-