5. Feature Selection and Dimensionality Reduction¶
In this section we are going to cover the basics of feature selection and dimensionality reduction. These methods allow us to represent our multi-dimensional data (with thousands of cells and thousands of genes) in a reduced set of dimensions for visualisation and more efficient downstream analysis.
In feature selection the principle is to remove those genes which are uninteresting or uninformative to both improve computation and because this ‘noise’ reduction will hopefully enable us to more clearly see the true biology in our data. We make the assumption that most of the low level variance is not caused by real biology and is due to stochastic sampling in the single cell protocol and various other technical effects. The genes which have the most variance are therefore the ones that reflect the real biological difference and are what we want to focus on. This is obviously not a perfect assumption but it is a good way to make informed interpretations from your data that you can hopefully have a little more confidence in.
In dimensionality reduction we attempt to find a way to represent all the the information we have in expression space in a way that we can easily interpret. High dimensional data has several issues. There is a high computational requirement to performing analysis on 30,000 genes and 48,000 cells (in the Caron dataset). Humans live in a 3D world; we can’t easily visualise all the dimensions. And then there is sparsity. As the number of dimensions increases the distance between two data points increases and becomes more invariant. This invariance causes us problems when we try to cluster the data into biologically similar groupings. By applying some dimensionality reducing methods we can solve these issues to a level where we can make interpretations
Setup
code
We will load the SingleCellExperiment object generated in the Normalisation section, which contains normalised counts for 500 cells per sample. For demonstration purposes we are not using the full dataset but you would in your analyses.
- To make some of our plots later on easier to interpret, we will replace the rownames of the object (containing Ensembl gene IDs) with the gene symbol. Sometimes it happens that there is no gene symbol and in some cases there are multiple genes with the same symbol (see e.g. RGS5). A safe way to handle these cases is to use theuniquifyFeatureNames() function, which will add the Ensembl gene id to symbols where necessary to distinguish between different genes
Feature Selection¶
We often use scRNA-seq data in exploratory analyses to characterize heterogeneity across cells. Procedures like clustering and dimensionality reduction compare cells based on their gene expression profiles, which involves aggregating per-gene differences into a single (dis)similarity metric between every pair of cells. The choice of genes to use in this calculation has a major impact on the behavior of the metric and the performance of downstream methods. We want to select genes that contain useful information about the biology of the system while removing genes that contain random noise. This aims to preserve interesting biological structure without the variance that obscures that structure, and to reduce the size of the data to improve computational efficiency of later steps.
The simplest approach to feature selection is to select the most variable genes based on their expression across the population. This assumes that genuine biological differences will manifest as increased variation in the affected genes, compared to other genes that are only affected by technical noise or a baseline level of “uninteresting” biological variation (e.g., from transcriptional bursting). Several methods are available to quantify the variation per gene and to select an appropriate set of highly variable genes (HVGs).
Quantifying per-gene variation¶
Some assays allow the inclusion of known molecules in a known amount covering a wide range, from low to high abundance: spike-ins. The technical noise is assessed based on the amount of spike-ins used, the corresponding read counts obtained and their variation across cells. The variance in expression can then be decomposed into the biological and technical components. There is discussion over whether this step is necessary but like all of the decisions you make in your analyses it would be wise to optimise your parameters and steps over several iterations with a view to existing biological knowlegde and controls.
The commonly used UMI-based assays do not (yet?) allow spike-ins. But one can still identify highly variable genes (HVGs), which likely capture biological variation. Assuming that, for most genes, the observed variance across cells is due to technical noise, we can assess technical variation by fitting a trend line between the mean-variance relationship across all genes. Genes that substantially deviate from this trend may then be considered as highly-variable, i.e. capturing biologically interesting variation. The scran function modelGeneVar with carry out this estimation for us.
The resulting output gives us a dataframe with all our genes and several columns. It has modeled the mean-variance relationship and from there it has estimated our total variance along with what it considers is the biological and technical variance.
code
gene_var %>%
as.data.frame() %>%
ggplot(aes(mean, total)) +
geom_point() +
geom_line(aes(y = tech), colour = "dodgerblue", size = 1) +
labs(x = "Mean of log-expression", y = "Variance of log-expression")
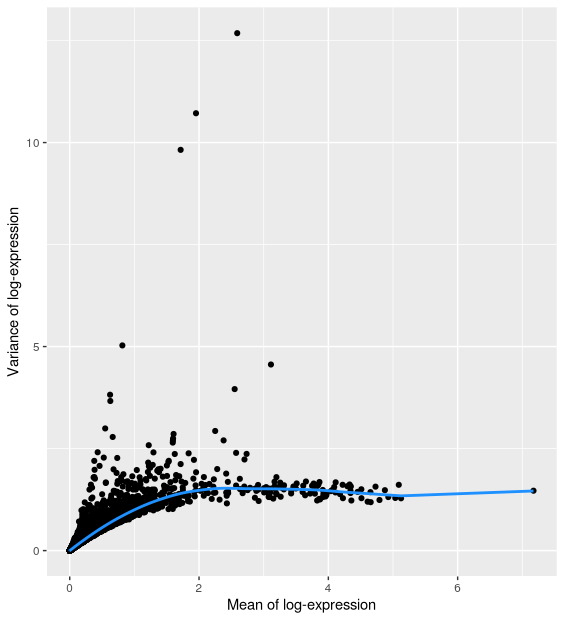
Selecting highly variable genes¶
Once we have quantified the per-gene variation, the next step is to select the subset of HVGs to use in downstream analyses. A larger subset will reduce the risk of discarding interesting biological signal by retaining more potentially relevant genes, at the cost of increasing noise from irrelevant genes that might obscure said signal. It is difficult to determine the optimal trade-off for any given application as noise in one context may be useful signal in another.
Commonly applied strategies are:
- take top X genes with largest (biological) variation
Top 1000 genes: getTopHVGs(gene_var, n=1000)
Top 10% genes: getTopHVGs(gene_var, prop=0.1)
- based on significance
getTopHVGs(gene_var, fdr.threshold = 0.05)
- keeping all genes above the trend
getTopHVGs(gene_var, var.threshold = 0)
- selecting a priori genes of interest
In our example, we will define ‘HVGs’ as the top 10% of genes with the highest biological component. This is a fairly arbitrary choice. A common practice is to pick an arbitrary threshold (either based on number of proportion) and proceed with the rest of the analysis, with the intention of testing other choices later, rather than spending much time worrying about obtaining the “optimal” value.
code
- The result is a vector of gene IDs ordered by their biological variance (i.e. highest deviation from the trend line shown above). We can use this with functions that accept a list of genes as option to restrict their analysis to that subset of genes (e.g. when we do PCA later on).- We can visualise the expression of the top most-variable genes with a violin plot for each gene using the
plotExpression()function:
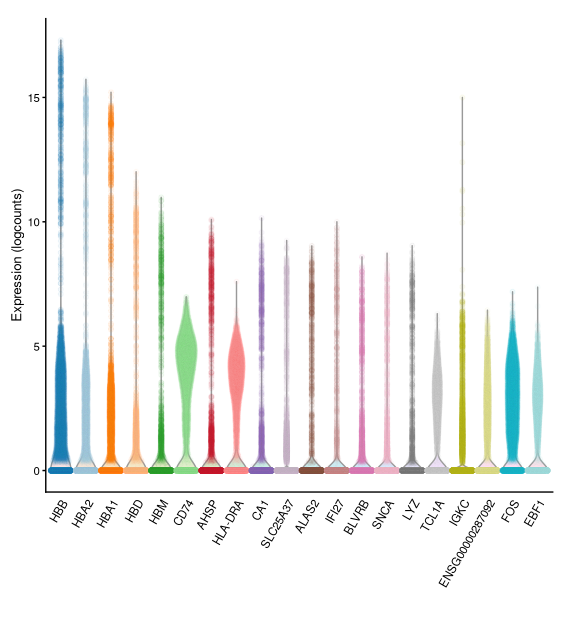
Dimensionality Reduction¶
Many scRNA-seq analysis procedures involve comparing cells based on their expression values across thousands of genes. Thus, each individual gene represents a dimension of the data (and the total number of genes represents the “dimensionality” of the data). More intuitively, if we had a scRNA-seq data set with only two genes, we could visualise our data in a two-dimensional scatterplot, with each axis representing the expression of a gene and each point in the plot representing a cell. Intuitively, we can imagine the same for 3 genes, represented as a 3D plot. Although it becomes harder to imagine, this concept can be extended to data sets with thousands of genes (dimensions), where each cell’s expression profile defines its location in the high-dimensional expression space.
As the name suggests, dimensionality reduction aims to reduce the number of separate dimensions in the data. This is possible because different genes are correlated if they are affected by the same biological process. Thus, we do not need to store separate information for individual genes, but can instead compress multiple features into a single dimension, e.g., an “eigengene” (Langfelder and Horvath 2007). This reduces computational work in downstream analyses like clustering, as calculations only need to be performed for a few dimensions, rather than thousands. It also reduces noise by averaging across multiple genes to obtain a more precise representation of the patterns in the data. And finally it enables effective visualisation of the data, for those of us who are not capable of visualizing more than 2 or 3 dimensions.
Here, we will cover three methods that are most commonly used in scRNA-seq analysis:
- Principal Components Analysis (PCA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Uniform Manifold Approximation and Projection (UMAP)
Before we go into the details of each method, it is important to mention that while the first method (PCA) can be used for downstream analysis of the data (such as cell clustering), the latter two methods (t-SNE and UMAP) should only be used for visualisation and not for any other kind of analysis.
Principal Components Analysis¶
One of the most used and well-known methods of dimensionality reduction is principal components analysis (PCA). This method performs a linear transformation of the data, such that a set of variables (genes) are turned into new variables called Principal Components (PCs). These principal components combine information across several genes in a way that best captures the variability observed across samples (cells).
Watch this video for more details on how PCA works:
After performing a PCA, there is no data loss, i.e. the total number of variables does not change. Only the fraction of variance captured by each variable differs.
Each PC represents a dimension in the new expression space. The first PC explains the highest proportion of variance possible. The second PC explains the highest proportion of variance not explained by the first PC. And so on: successive PCs each explain a decreasing amount of variance not captured by the previous ones.
The advantage of using PCA is that the total amount of variance explained by the first few PCs is usually enough to capture most of the signal in the data. Therefore, we can exclude the remaining PCs without much loss of information. The stronger the correlation between the initial variables, the stronger the reduction in dimensionality. We will see below how we can choose how many PCs to retain for our downstream analysis.
Running PCA¶
SingleCellExperiment objects contain a slot that can store representations of our data in reduced dimensions. This is useful as we can keep all the information about our single-cell data within a single object.
The runPCA() function can be used to run PCA on a SCE object, and returns an updated version of the single cell object with the PCA result added to the reducedDim slot.
Importantly, we can also restrict the PCA to use only some of the features (rows) of the object, which in this case we do by using the highly variable genes we identified earlier.
code
- We can see that the output shows a new
reducedDimNamesvalue called “PCA”. We can access it by using thereducedDim()function:
runPCA() returns the first 50 PCs, but you can change this number by specifying the ncomponents option.
One of the first things to investigate after doing a PCA is how much variance is explained by each PC. This information is stored as an “attribute” (think of it as additional information) attached to the PCA matrix above. The typical way to view this information is using what is known as a “scree plot”.
percent.var <- attr(reducedDim(sce), "percentVar")
plot(percent.var, log="y", xlab="PC", ylab="Variance explained (%)")
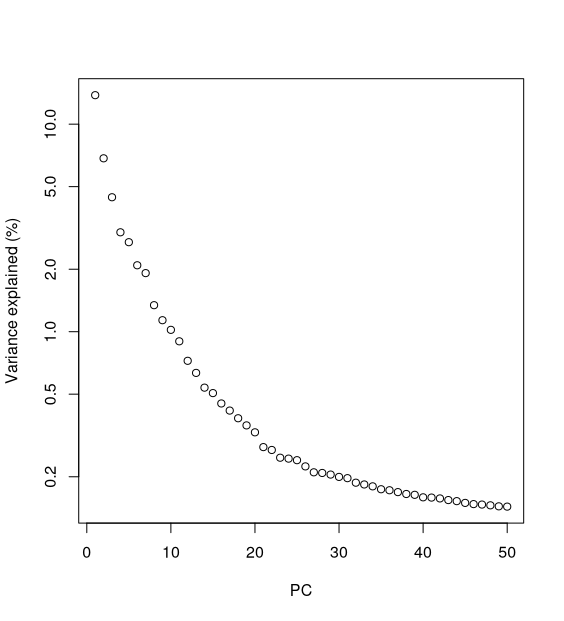
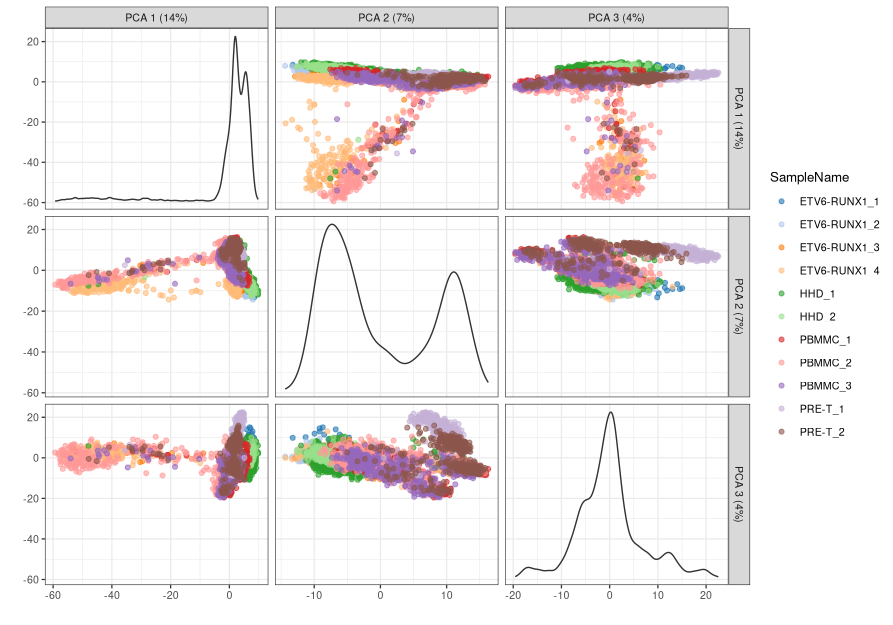
- We can see how the two first PCs explain a substantial amount of the variance, and very little variation is explained beyond 10-15 PCs. To visualise our cells in the reduced dimension space defined by PC1 and PC2, we can use the
plotReducedDim()function.

-
The proximity of cells in this plot reflects the similarity of their expression profiles.
-
We can also plot several PCs at once, using the
ncomponentsoption:
Although these plotting functions are useful for quickly visualising our data, more customised visualisations can be used by using the ggcells() function, which extends the regular ggplot() function, but to work directly from the SCE object. We can use it in a similar manner as we use the regular ggplot() function, except we can define aesthetics both from our reducedDim slot as well as colData and even assays (to plot particular gene’s expression). Here is an example, where we facet our plot:
ggcells(sce, aes(x = PCA.1, y = PCA.2, colour = SampleName)) +
geom_point(size = 0.5) +
facet_wrap(~ SampleName) +
labs(x = "PC1", y = "PC2", colour = "Sample")

PCA Diagnostics¶
There are a large number of potential confounders, artifacts and biases in scRNA-seq data. One of the main challenges stems from the fact that it is difficult to carry out true technical replication to distinguish biological and technical variability. Here we will continue to explore how experimental artifacts can be identified and removed.
One of the ways to achieve this is to calculate the association between our PC scores and different variables associated with our cells such as sample groups, number of detected genes, total reads per cell, percentage of mitochondrial genes, etc. We can achieve this using the getExplanatoryPCs() function (and associated plotting function), which calculates the variance in each PC explained by those variables we choose:
code
explain_pcs <- getExplanatoryPCs(sce,
variables = c("sum",
"detected",
"SampleGroup",
"SampleName",
"subsets_Mito_percent")
)
plotExplanatoryPCs(explain_pcs/100)
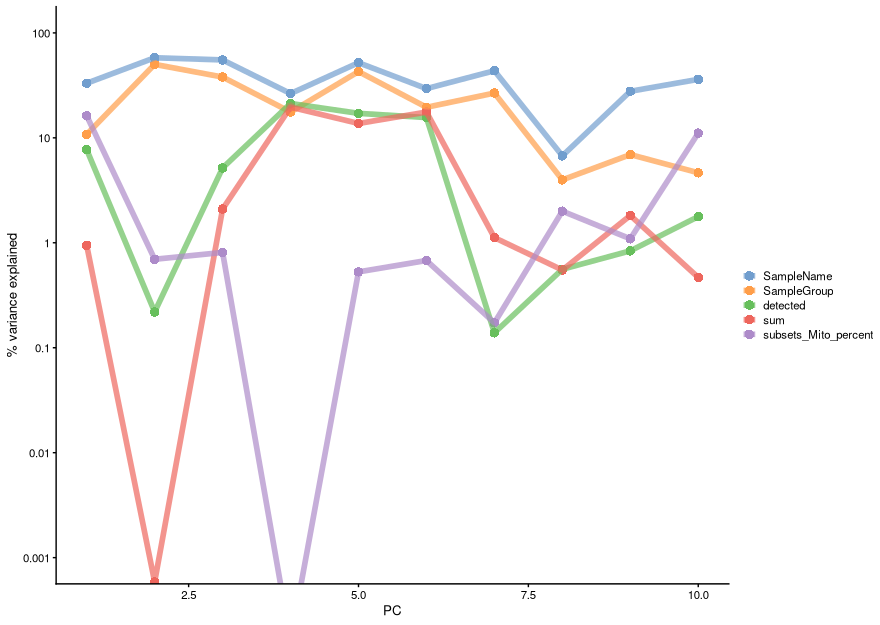
We can see that PC1 can be explained mostly by individual samples (SampleName), mitochondrial expression and mutation group (SampleGroup).
We can also compute the marginal R2 for each variable when fitting a linear model regressing expression values for each gene against just that variable, and display a density plot of the gene-wise marginal R2 values for the variables.
code
plotExplanatoryVariables(sce,
variables = c(
"sum",
"detected",
"SampleGroup",
"SampleName",
"subsets_Mito_percent"
))
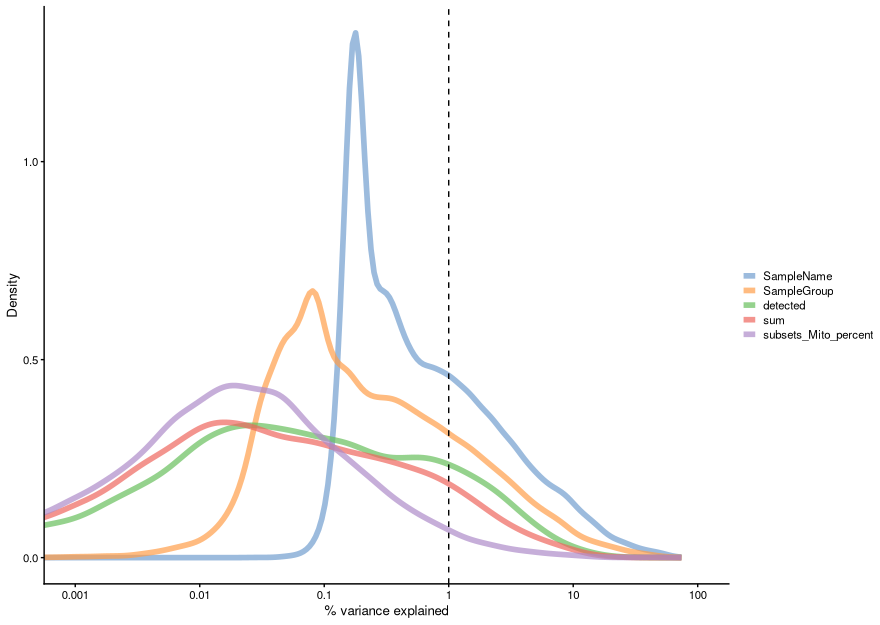
This analysis indicates that individual and subtype have the highest explanatory power for many genes, and we don’t see technical covariates having as high correlations. If that were the case, we might need to repeat the normalization step while conditioning out for these covariates, or we would include them in downstream analysis.
Choosing the number of PCs¶
The choice of the number of PCs we retain for downstream analyses is a decision that is analogous to the choice of the number of HVGs to use. Using more PCs will retain more biological signal at the cost of including more noise that might mask said signal. Much like the choice of the number of HVGs, it is hard to determine whether an “optimal” choice exists for the number of PCs. Even if we put aside the technical variation that is almost always uninteresting, there is no straightforward way to automatically determine which aspects of biological variation are relevant; one analyst’s biological signal may be irrelevant noise to another analyst with a different scientific question.
Most practitioners will simply set the number of PCs to a “reasonable” but arbitrary value, typically ranging from 10 to 50. This is often satisfactory as the later PCs explain so little variance that their inclusion or omission has no major effect. For example, in our dataset, few PCs explain more than 1% of the variance in the entire dataset.
The most commonly used strategies to choose PCs for downstream analysis include:
- selecting the top X PCs (with X typically ranging from 10 to 50)
- using the elbow point in the scree plot
- using technical noise
- using permutation
Elbow Point¶
To choose the elbow point in our scree plot, we can use the following:
code
- Here is our scree plot again, but this time with a vertical line indicating the elbow point:
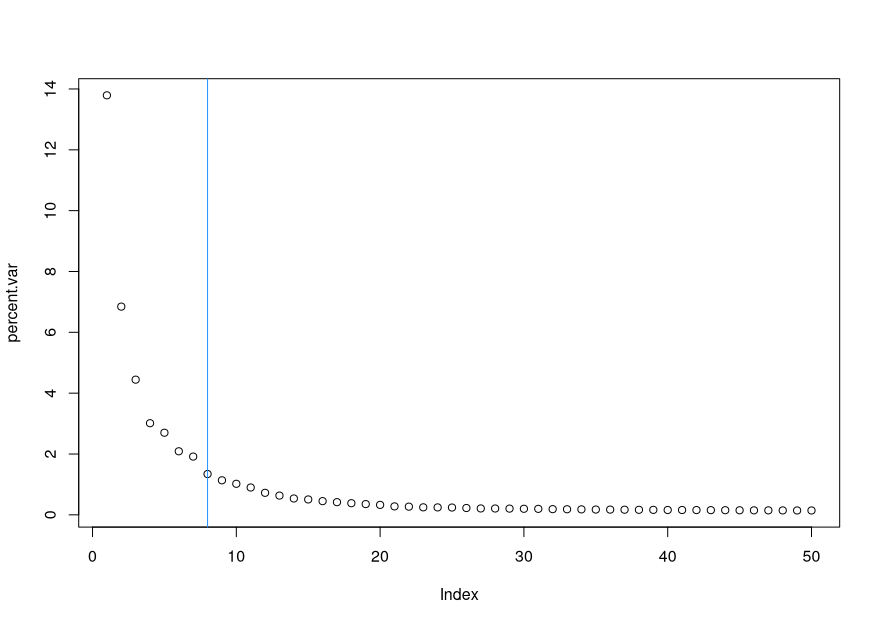
Alternatives to the elbow point method: denoising PCA and permutation
Denoising PCA¶
The assumption of this method is that the biology drives most of the variance and hence should be captured by the first few PCs, while technical noise affects each gene independently, hence it should be captured by later PCs. Therefore, our aim in this approach is to find the minimum number of PCs that explains more variance than the total technical variance across genes (estimated from our mean-variance trend).
code
This method is implemented in the denoisePCA() function:
If we look at our PCA result, we can see that it has 6 columns.
Permutation¶
We do not demonstrate this method, as it is more code intensive. The idea is to permute (or “shuffle”) a subset of the data, rerun the PCA and calculate the percentage of variance explained by each PC on this “random” dataset. We can then compare the observed variance explained in the original data with this null or random expectation and determine a cutoff where the observed variance explained drops to similar values as the variance explained in the shuffled data.
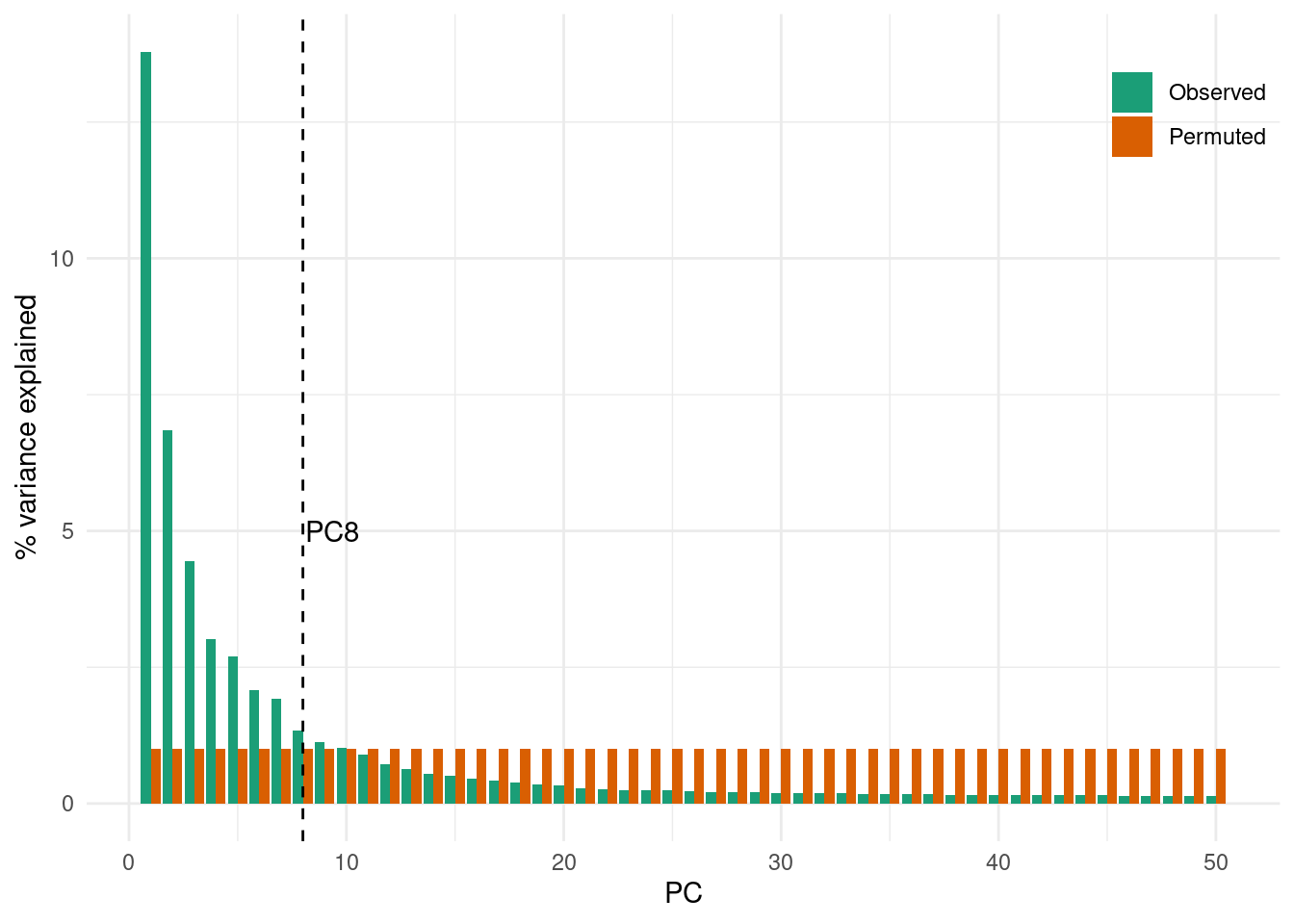
t-SNE: t-Distributed Stochastic Neighbor Embedding¶
The t-Distributed Stochastic Neighbor Embedding (t-SNE) approach addresses the main shortcoming of PCA, which is that it can only capture linear transformations of the original variables (genes). Instead, t-SNE allows for non-linear transformations, while preserving the local structure of the data. This means that neighbourhoods of similar samples (cells, in our case) will appear together in a t-SNE projection, with distinct cell clusters separating from each other.
As you can see below, compared to PCA we get much tighter clusters of samples, with more structure in the data captured by two t-SNE axis, compared to the two first principal components.
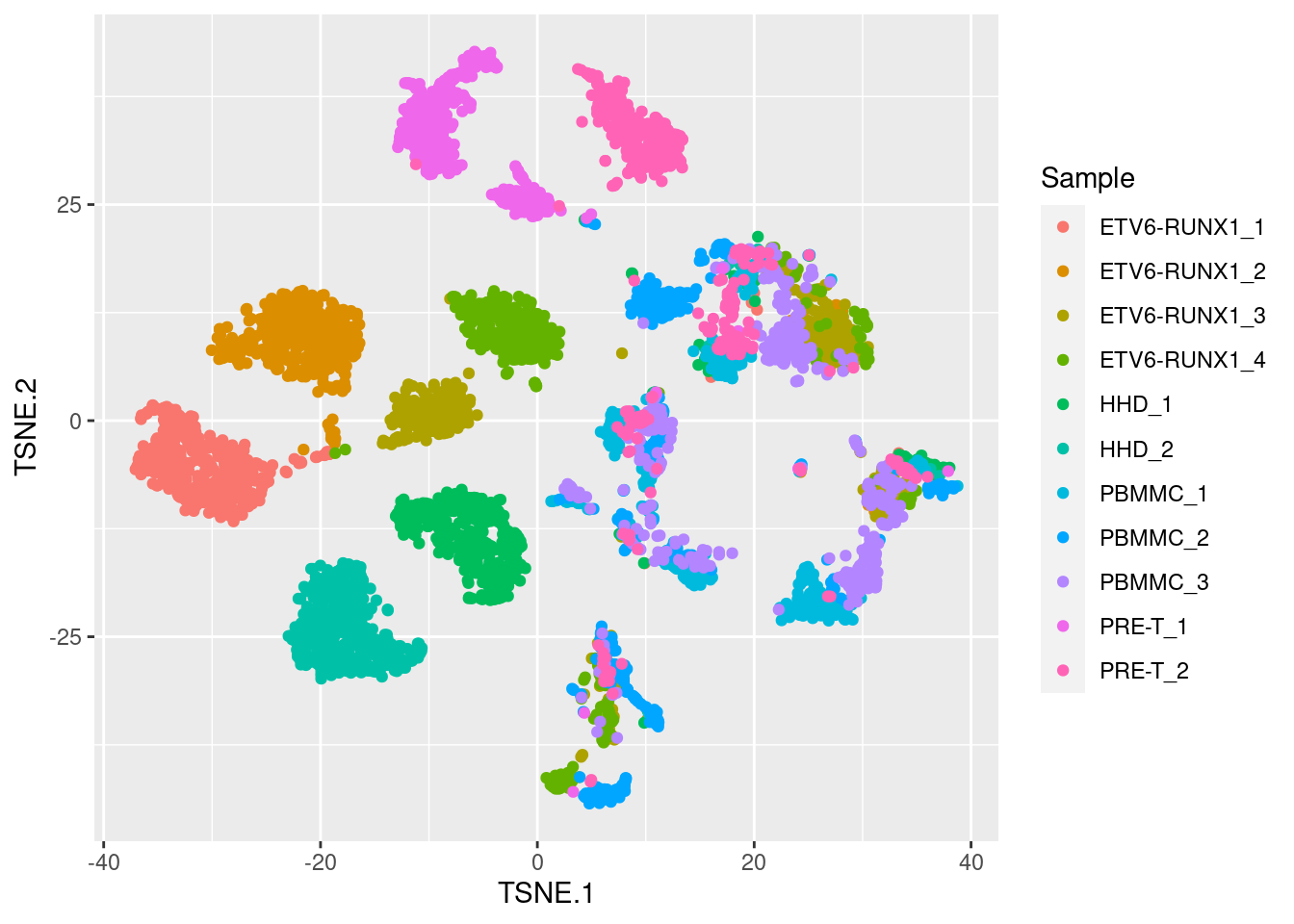
We will not go into the details of the algorithm here, but briefly it involves two main steps:
-
Calculating a similarity matrix between every pair of samples. This similarity is scaled by a Normal distribution, such that points that are far away from each other are “penalised” with a very low similarity score. The variance of this normal distribution can be thought of as a “neighbourhood” size when computing similarities between cells, and is parameterised by a term called perplexity.
-
Then, samples are projected on a low-dimensional space (usually two dimensions) such that the similarities between the points in this new space are as close as possible to the similarities in the original high-dimensional space. This step involves a stochastic algorithm that “moves” the points around until it converges on a stable solution. In this case, the similarity between samples is scaled by a t-distribution (that’s where the “t” in “t-SNE” comes from), which is used instead of the Normal to guarantee that points within a cluster are still distinguishable from each other in the 2D-plane (the t-distribution has “fatter” tails than the Normal distribution).
Watch this video to learn more about how t-SNE works:
There are two important points to remember:
- the perplexity parameter, which indicates the relative importance of the local and global patterns in the structure of the data set. The default value in the functions we will use is 50, but different values should be tested to ensure consistency in the results.
- stochasticity: because the t-SNE algorithm is stochastic, running the analysis multiple times will produce slightly different results each time (unless we set a “seed” for the random number generator).
See this interactive article on “How to Use t-SNE Effectively”, which illustrates how changing these parameters can lead to widely different results.
Importantly, because of the non-linear nature of this algorithm, strong interpretations based on how distant different groups of cells are from each other on a t-SNE plot are discouraged, as they are not necessarily meaningful. This is why it is often the case that the x- and y-axis scales are omitted from these plots (as in the example above), as they are largely uninterpretable. Therefore, the results of a t-SNE projection should be used for visualisation only and not for downstream analysis (such as cell clustering).
Running t-SNE¶
Similarly to how we did with PCA, there are functions that can run a t-SNE directly on our SingleCellExperiment object. We will leave this exploration for you to do in the following exercises, but the basic code is very similar to that used with PCA. For example, the following would run t-SNE with default options:
code
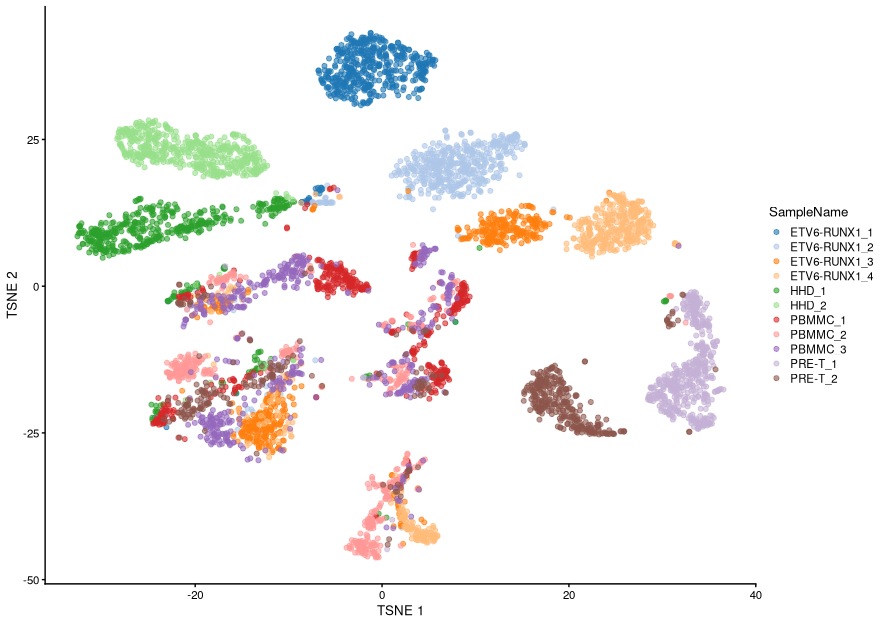
One thing to note here is that, because of the computational demands of this algorithm, the general practice is to run it on the PCA results rather than on the full matrix of normalised counts. The reason is that, as we’ve seen earlier, the first few PCs should capture most of the biologically meaningful variance in the data, thus reducing the influence of technical noise in our analysis, as well as substantially reducing the computational time to run the analysis.
UMAP: Uniform Manifold Approximation and Projection¶
Simiarly to t-SNE, UMAP performs a non-linear transformation of the data to project it down to lower dimensions. One difference to t-SNE is that this method claims to preserve both local and global structures (i.e. the relative positions of clusters are, most of the times, meaningful). However, it is worth mentioning that there is some debate as to whether this is always the case, as is explored in this recent paper by Chari, Banerjee and Pachter (2021).
Compared to t-SNE, the UMAP visualization tends to have more compact visual clusters with more empty space between them. It also attempts to preserve more of the global structure than t -SNE. From a practical perspective, UMAP is much faster than t-SNE, which may be an important consideration for large datasets.
Similarly to t-SNE, since this is a non-linear method of dimensionality reduction, the results of a UMAP projection should be used for visualisation only and not for downstream analysis (such as cell clustering).
Running UMAP¶
code
Running UMAP is very similar to what we’ve seen already for PCA and t-SNE, only the function name changes:

Because this UMAP also involves a series of randomization steps, setting the random-generator seed (as we did above) is critical if we want to obtain reproducible results after each run.
Like t-SNE, UMAP has its own suite of hyperparameters that affect the visualization. Of these, the number of neighbors (n_neighbors) and the minimum distance between embedded points (min_dist) have the greatest effect on the granularity of the output. If these values are too low, random noise will be incorrectly treated as high-resolution structure, while values that are too high will discard fine structure altogether in favor of obtaining an accurate overview of the entire dataset. Again, it is a good idea to test a range of values for these parameters to ensure that they do not compromise any conclusions drawn from a UMAP plot.
See this interactive article that goes into more depth about the underlying methods, and explores the impacts of changing the n_neighbours and min_dist parameters: Understanding UMAP.
Similarly to what we did with t-SNE, we will explore this further in the following exercise.
Exercise - fill in the missing lines of following code
- Our main objectives are:
- Add a UMAP projection of the data to our SCE object
- Explore how the main tuneable parameter of the algorithm - neighbourhood size - affects the results
- Compare how UMAP compares to t-SNE in terms of revealing structure in the data
code
# Run UMAP ----
# Part A
# run the UMAP with 50 neighbours
set.seed(123) # set seed for reproducibility
sce <- runUMAP(sce,
name = "UMAP_neighbors50",
dimred = "PCA",
FIXME)
# Part B
# visualise the resulting UMAP projection (colour cells by sample)
# Part C
# run the UMAP with 5 and 500 neighbours and compare the results
# Part D
# compare the UMAP projection with the t-SNE projections
# would you prefer one over the other?
Hint
- Check out the ?runUMAP help page, there should be an argument for fixing the number of nearest neighbours.
- You can use the same code as for plotting the TSNE but replacing the arguments to display the UMAP output data.
- Change the number of neighbours argument in the runUMAP() function to see what changes.
- Redraw the TSNE and compare it with your UMAP.
Answer
# Run UMAP ----
# run the UMAP with 50 neighbours
set.seed(123) # set seed for reproducibility
sce <- runUMAP(sce,
name = "UMAP_neighbors50",
dimred = "PCA",
n_neighbors = 50)
# visualise the resulting UMAP projection
# colour cells by sample
ggcells(sce, aes(x = UMAP_neighbors50.1, y = UMAP_neighbors50.2,
colour = SampleName)) +
geom_point()
# run the UMAP with 5 and 500 neighbours and compare the results
set.seed(123) # set seed for reproducibility
sce <- runUMAP(sce,
name = "UMAP_neighbors5",
dimred = "PCA",
n_neighbors = 5)
sce <- runUMAP(sce,
name = "UMAP_neighbors500",
dimred = "PCA",
n_neighbors = 500)
ggcells(sce, aes(x = UMAP_neighbors5.1, y = UMAP_neighbors5.2,
colour = SampleName)) +
geom_point() +
labs(title = "Neighbours = 5")
ggcells(sce, aes(x = UMAP_neighbors500.1, y = UMAP_neighbors500.2,
colour = SampleName)) +
geom_point() +
labs(title = "Neighbours = 500")
# compare the UMAP projection with the t-SNE projections
# would you prefer one over the other?
sce <- runTSNE(sce, perplexity = 50, name="TSNE_perplex50")
ggcells(sce, aes(x = TSNE_perplex50.1, y = TSNE_perplex50.2,
colour = SampleName)) +
geom_point()
ggcells(sce, aes(x = UMAP_neighbors50.1, y = UMAP_neighbors50.2,
colour = SampleName)) +
geom_point()
Save SCE object¶
Optionally, we can save our object, which now contains our dimensionality reduction analysis in it. This is useful as it will save time next time we pick up on our analysis.